Plant Smart Monitoring System
- #Agritech
- #AI & Machine Learning
- #Computer Vision
- #Deep learning
- #Greenhouse
About the Client
A startup that uses AI to monitor plants for early-stage disease detection.
Business Challenge
Agricultural companies are widely adopting high-tech solutions to optimize business processes. But sometimes, there is still a lack of knowledge on how to build an end-to-end pipeline for particular tasks cost-effectively.
Since farm income depends on the yield level, plant growth monitoring and disease prevention are crucial for maximizing outcomes and especially valuable for high-profit plants, such as medical cannabis. Aiming to automate the manual labor of gardeners observing hemp plants, our client decided to adopt emerging technologies with the help of Quantum.
Solution Overview
At the beginning of our partnership, the company was a ready-made startup but its technological approach couldn’t cover all the business needs. In particular:
- To distinguish the growth cycle phases of hemp and gain insights on harvesting.
- To detect hemp disease symptoms, such as gray/yellowish leaves and rash/stains on the leaves.
Using advanced image processing techniques, we handled all the abovementioned issues and created a complex data analytics pipeline to monitor plant growth and detect and classify disease at the early stages.
As a result, our model worked with 11 classes with an accuracy of 90%, helping the staff save nearly 25% of the crop with timely treatment or withdrawal of the affected plants.
Our particular approach also allowed us to optimize infrastructure costs by using fewer masses of data while maintaining the accuracy of our analytics.

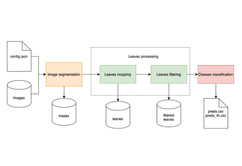
Project Description
Hemp flower detection with 80% accuracy. The detection accuracy directly depends on the data preparation process – in this case, image segmentation by the cannabis growth stage. The obtained datasets were used to train models customized for each data type so that we could choose the best-performing one.
Automatic disease classification with 90% accuracy. We used a similar approach to create a deep learning model capable of identifying 11 different types of leaves and in-depth health analysis. This model recognized a specific disease by identifying different symptoms and relations between them.
Read about the technical side of the project in detail in our article.
Let's discuss your idea!








Technological Details
We use a wide technological stack for this project, including Python, PyTorch, Docker-Nvidia, OpenCV, and Scikit-Image.