LLMs: Everything you need to know

Michael Yushchuk
Head of Data Science
What are the Large Language Models?
Large language models (LLMs) are powerful AI models designed to understand and generate human-like text. They use massive amounts of data to learn patterns in language, allowing them to answer questions, generate content, and perform various language-related tasks.
How powerful are LLMs
Large language models work in a few key steps. Initially, they learn from tons of text to understand grammar, context, and general knowledge. Text gets segmented into smaller units called tokens, and neural networks process these tokens to transform input into meaningful output. Afterward, the model undergoes fine-tuning for specific tasks, like answering questions or generating text, and then, during inference, produces output, like generating text or answering questions.
Handling large amounts of data: talking numbers
Language models vary in size and capabilities. For example, GPT-3 was trained on a vast 570 GB of text data. In contrast, the previous generation’s state-of-the-art BERT model had a training dataset of only 16 GB of text.
To give you some perspective, a 1 GB text file can hold roughly 178 million words. Just think about the immense number of words used to train even the smallest one from LLMs! This way, you could input an entire book into these models. Yes, it might be costly, but it’s definitely feasible!
Adaptability to different domains
Large language models possess remarkable versatility and can work with data from any field without delving into domain-specific details. However, to truly excel in a specific topic, they require fine-tuning tailored to that particular domain. This adaptability empowers them to comprehend and produce relevant content across various fields, including finance, healthcare, or even your favorite hobby.
Which tasks do LLMs solve?
LLMs are highly adaptable and can tackle various NLP tasks. These include text generation, translation, text summarization, classification, sentiment analysis, conversational AI, and chatbots. Let’s take a closer look at some of these tasks:
Named Entity Recognition & Relation Extraction
LLMs can identify specific entities in textual data, such as names, places, or organizations, such as the name “Mike” and the institution “MIT,” and establish connections based on their relationships, like “Mike is studying at MIT.” It is essential for organizing and categorizing information effectively, especially if you need to process massive documents.
Sentiment & Intent analytics
Large language models excel in analyzing language to determine the intent behind a user’s query or message and whether it expresses a positive, negative, or neutral sentiment. This capability is crucial for businesses to gauge brand loyalty and make informed decisions.
AI Chatbots & Virtual Assistants
LLM-powered chatbots are invaluable for customer success. A deep understanding of language and domain data enables them to engage in natural conversations and intuitive user interactions. As an example, check our LLM-based financial advisory chatbot for instant investment advice.
ChatGPT and GPT-based models
First things first, ChatGPT isn’t a standalone model; it’s a composite system comprising GPT-3.5 Turbo and GPT-4 models.
GPT-3.5 Turbo is a powerful language model known for its impressive ability to understand and generate human-like text. However, some businesses, especially those requiring advanced language understanding, might fail from GPT-3.5 and require GPT-4 integration.
GPT-4 is relevant for industries such as legal services for in-depth case analysis or complex scientific research, where its enhanced capabilities in understanding context and generating more accurate and contextually relevant text can be valuable.
However, there are concerns about data privacy since sensitive data passes through OpenAI servers, and there are no alternative options for keeping it in-house. These considerations are crucial when leveraging these advanced language models for specific applications.
Open-source large language models
Custom open-source LLMs may not match the scale of GPT-4, but they offer the flexibility of fine-tuning for various tasks, which GPT-based models handle as well. However, there is one thing: open-source LLMs are way easier to fine-tune on specific-domain tasks.
Let’s say you need a chatbot therapeutist that can make an initial diagnosis or direct users to specialized doctors based on the same symptoms. In such case, a pre-trained open-source LLM fine-tuned on specific domain data will definitely excel where GPT-4 falls short.
Most open-source LLMs are available on Hugging Face, accessible via the Transformers library. Since this is a rapidly evolving field, the top open-source LLM models change almost monthly.
On the day of writing this article, the Open LLM Leaderboard appeared as follows:

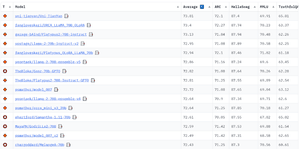
The competitive advantage of open-source LLMs lies in data privacy, as they host the model within their infrastructure. This means you can access the source code, understand the model’s operation, and verify its behavior, which can be crucial for ensuring ethical and unbiased outputs. So, choosing a suitable model for specific data needs requires significant consideration.
Large Language Models deployment
When it comes to deployment, for OpenAI models, the process is straightforward and transparent – you can purchase an API and integrate it into your application.
Deploying open-source LLMs can be costly, especially when handling substantial data loads. It also requires the use of less obvious optimization methods to guarantee speedy performance. However, at Quantum, we’ve implemented several effective strategies in our projects that helped optimize the model operations while managing the costs without compromising the quality.
Feel free to reach out if you’d like to delve deeper into this.
Working with open-source language models may present challenges, but their capabilities are really worth it. Embracing the potential of open-source language models can result in text analysis and generation solutions that are more accurate, context-aware, and efficient.
Prompt engineering for accurate outputs
Prompt engineering is carefully crafting and refining the prompts or instructions that serve as helpful add-ons transmitted in model requests to guide responses. These prompts specify what to answer, how to respond, which words to use or avoid, the recommended answer length, and the chatbot’s role.
This feature allows us to configure the model as needed, obtain the proper answer, and seamlessly switch between tasks.
You can learn more about prompt strategies for different purposes in our article: “How to build question-answering system using LLM.”


Looking Ahead of LLM’s Future
The latest advancements in LLM technology will likely begin a new era of automation and efficiency across various industries. We can anticipate LLMs being employed in healthcare, finance, and education solutions to streamline processes and provide valuable insights. However, it comes with the responsibility of ensuring ethical utilization and a solid commitment to protecting user data.
As LLMs keep improving, it’s vital to establish strong data protection and clear AI usage rules. Also, ongoing research should tackle biases and promote fairness in AI to avoid unintended issues and ensure these innovations benefit society.
LLM-powered solution development
Discover how custom LLM agents can streamline decision-making, automate workflows, and unlock new AI-driven value across your organization.
Check the service






