How to build question answering system using LLM

Michael Yushchuk
Head of Data Science
Introduction to Large Language Models
In recent years, Language Models (LMs) have significantly impacted natural language processing (NLP), revolutionizing how we interact with computers and pushing the boundaries of what machines can understand and generate. One such groundbreaking development is the advent of Large Language Models (LLMs), which have opened up a realm of possibilities previously unimaginable. LLMs, powered by advanced algorithms and trained on vast amounts of data, can understand, generate, and manipulate human language with astonishing accuracy and creativity.
This article aims to delve into the exciting world of LLMs, highlighting a brief overview of their architecture and application techniques.
Understanding LLMs
LLMs are state-of-the-art artificial intelligence systems that have the remarkable ability to understand and generate human language. At their core, LLMs are built upon advanced deep learning architectures, such as transformer models, which have revolutionized the field of NLP. These models consist of multiple layers of self-attention mechanisms and feed-forward neural networks, allowing them to capture complex language patterns, dependencies, and contextual information.
A typical transformer model consists of four main steps in processing input data.
First, the model performs word embedding to convert words into high-dimensional vector representations. Then, the data is passed through multiple transformer layers. Within these layers, the self-attention mechanism is crucial in understanding the relationships between words in a sequence. Finally, after processing through the transformer layers, the model generates text by predicting the most likely next word or token in the sequence based on the learned context.

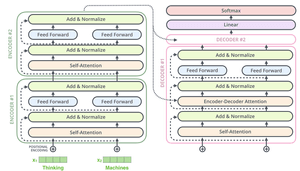
The concept of self-attention enables the model to focus on different parts of the input text to understand the relationships between words and their significance within the context. It works by assigning weights to different words in a given input sequence based on their relevance and importance in the context. Each word in the sequence attends to all other words, calculating a weighted representation of their contributions to its representation. These weights are determined by computing the dot product of the word’s embedding and the embeddings of the other words, followed by applying a softmax function to obtain normalized attention scores.
By attending to relevant words and phrases, LLMs can generate coherent and contextually appropriate responses that follow a given text input with an instruction to an LLM. This text instruction is called a prompt.


LLMs have greatly enhanced language understanding capabilities. They can accurately comprehend and interpret text inputs by capturing intricate language patterns and contextual cues. Models adapt their pre-trained knowledge to specific tasks through transfer learning, reducing training time. LLMs also possess zero-shot capabilities, generating responses without explicit training. This has profound implications for various NLP tasks such as sentiment analysis, information retrieval, and question answering, where they have proven instrumental in providing accurate and contextually relevant responses.
LLMs have also revolutionized human-machine interactions by enabling more natural and intuitive communication. Through chatbots and virtual assistants powered by LLMs, users can engage in conversations that feel remarkably close to conversing with a human. This has improved customer service experiences, streamlined information retrieval, and facilitated personalized user interactions.
The release of GPT-3 (Generative Pre-trained Transformer 3) marked significant milestones in developing and deploying large-scale language models. Released by OpenAI in June 2020, the model captured widespread attention due to its unprecedented size and capabilities. With 175 billion parameters, GPT-3 demonstrated remarkable language generation and understanding abilities, leading to human-like text responses.
However, proprietary models like GPT-3 have garnered significant attention and demonstrated impressive capabilities, and they do come with several disadvantages. One primary concern is the cost structure associated with proprietary models. GPT-3 can be expensive as it operates on a token-based pricing model, where users are charged for every 1,000 tokens processed.
Another drawback is latency issues that may arise as the models rely on remote servers, introducing processing delays unsuitable for real-time applications. Additionally, a lack of flexibility comes with proprietary models. Their underlying architectures and parameters are typically inaccessible for modification, limiting the ability to fine-tune the models according to specific use cases or domains.
In response to the centralization of LLM power, the open-source community has actively worked on developing alternative models that promote transparency, accessibility, and community-driven development. One notable example is the LLaMA, a family of LLMs in four sizes: 7, 13, 33, and 65 billion parameters. LLaMa is not an instruction-following LLM like ChatGPT, but the idea behind the smaller size of LLaMA is that smaller models pre-trained on more tokens are easier to retrain and fine-tune for specific tasks and use cases. Although the LLaMA was released under “a noncommercial license focused on research use cases,” models with a commercial use license were released quickly.
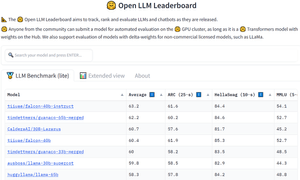
Falcon is the first fully open-source large language model, and it has outranked all the open-source models released so far, including LLaMA, StableLM, MPT, and more. It has been developed by the Technology Innovation Institute (TII), UAE. So far, the TII has released two Falcon models trained on 40B and 7B parameters.

Techniques of using LLMs
When it comes to inference LLMs, several techniques have emerged to guide the generation of desired outputs. The four major ones are:
- Zero-shot prompting
- Few-shot prompting
- Fine-tuning
- Embedding


Zero-shot Prompting
Zero-shot prompting means providing a prompt that is not part of the training data to the model, but the model can generate a result that you desire. This capability stems from their extensive pre-training on massive amounts of diverse text data, which equips them with a broad understanding of human language. During pre-training, LLMs learn to capture patterns, contextual relationships, and semantic representations from the data they are trained on. As a result, when presented with a question, LLMs can leverage their acquired knowledge to generate responses that align with the query.
Utilizing zero-shot prompting is an excellent initial step to swiftly assess the capabilities of LLMs and obtain responses without the need for specialized training. This approach only requires the construction of a prompt, making it a straightforward way to evaluate the LLM’s performance and explore its language understanding abilities. However, it’s essential to note that zero-shot prompting may not always yield accurate or desired results. In such cases, few-shot prompting can be a more practical approach.
Let’s demonstrate a use case of zero-shot prompting for named entity recognition (NER). To perform NER using zero-shot prompting, we construct a prompt that specifies the task as well as the entity types to be identified.
Prompt: Identify the entities in the following text and tag them as PERSON, ORGANIZATION, LOCATION, or PRODUCT.
Text: John Smith is a software engineer at Google. He lives in Mountain View, California.
The LLM, equipped with its pre-trained knowledge, comprehends the prompt and applies its understanding to identify the named entities in the text. In this example, the LLM would recognize “John Smith” as a PERSON, “Google” as an ORGANIZATION, and “Mountain View” as a LOCATION. By employing zero-shot prompting, LLMs can effectively perform named entity recognition tasks without requiring specific training on labeled data for each entity type.
Few-shot Prompting
Few-shot prompting presents a set of high-quality demonstrations of the target task, each consisting of both input and desired output. As the model first sees good examples, it can better understand human intention and criteria for what kinds of answers are wanted. Therefore, few-shot prompting often leads to better performance than zero-shot. However, it comes at the cost of more token consumption and may hit the context length limit when input and output text is long.
This technique proves exceptionally advantageous in several situations where fine-tuning or extensive training may not be feasible or efficient. Firstly, when dealing with limited labeled data for a specific task, few-shot prompting becomes valuable. By providing a small set of relevant examples, the model can quickly learn and generalize from this limited data, enabling it to perform well on the given task. Secondly, few-shot prompting is helpful for rapid prototyping and experimentation. It allows developers to iteratively test and refine models without requiring time-consuming fine-tuning processes.
Few-shot prompting demonstrates a wide range of use cases, including enhancing Natural Language Understanding (NLU) tasks like sentiment analysis, entity recognition, and relationship extraction. It improves question-answering systems by generating accurate responses through demonstrations of correct answers. In text summarization, it aids in generating concise and informative summaries. For conversational AI applications, it guides models to produce context-aware and coherent responses, while in data extraction and formatting tasks, it helps extract and organize information into structured formats.
To illustrate the concept of few-shot prompting, let’s consider an example in which we attempt to classify customer feedback as positive or negative. We provide a model with 3 examples of positive/negative feedback, then show it a new piece of feedback that has yet to be classified.
Prompt:
The product is fantastic, delivering excellent quality and exceeding my expectations in every way: positive
I’m disappointed with the poor customer service and lack of responsiveness to inquiries and concerns: negative
I absolutely love this! It’s user-friendly, durable, and provides exceptional value for the price: positive
Unfortunately, the product did not live up to its claims and fell short in terms of performance and durability:
The model sees that the first 3 examples were classified as either positive or negative and uses this information to classify the new example as negative. We can observe that the model has somehow learned how to perform the task by providing it with just 3 examples (i.e., 3-shot). For more complex tasks, we can experiment with increasing the number of demonstrations (e.g., 5-shot, 10-shot, etc.).
Fine-tuning
In some instances, few-shot prompting may not effectively address a specific use case or deliver the desired results. In such situations, fine-tuning becomes a more suitable option to tailor LLM to the targeted application.
Fine-tuning involves adjusting the parameters of a pre-trained model to improve its performance on a particular task. By supplying the model with a curated dataset of relevant examples, fine-tuning allows the LLM to generate more accurate and context-specific responses. This process is especially beneficial for tasks that demand a deeper understanding of domain-specific terminology, jargon, or unique context that may not be sufficiently captured through few-shot prompting, for instance, customer service chatbots.
It is worth mentioning that fine-tuning LLMs presents its own set of challenges. For example, to fine-tune a 65 billion parameters model, we need more than 780 Gb of GPU memory. It is equivalent to ten A100 80 Gb GPUs. In other words, you would need cloud computing to fine-tune your models.
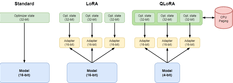
To overcome the issue of memory usage during fine-tuning, Dettmers et al. presented QLoRA: Efficient Fine-tuning of Quantized LLMs. QLoRA employs an efficient approach that enables fine-tuning a 65B parameter model on a single 48GB GPU.
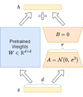
QLoRA utilizes a technique called Low-Rank Adapters (LoRA) which adds a tiny amount of trainable parameters, i.e., adapters, for each layer of the LLM and freezes all the original parameters. We only have to update the adapter weights for fine-tuning, significantly reducing the memory footprint.

Next QLoRa goes three steps further by introducing: 4-bit quantization, double quantization, and the exploitation of nVidia unified memory for paging.
In a few words, each one of these steps works as follows:
- 4-bit NormalFloat quantization: This is a method that improves upon quantile quantization. It ensures an equal number of values in each quantization bin. This avoids computational issues and errors for outlier values.
- Double quantization: The authors of QLoRa define it as follows: “the process of quantizing the quantization constants for additional memory savings.”
- Paging with unified memory: It relies on the NVIDIA Unified Memory feature and automatically handles page-to-page transfers between the CPU and GPU. It ensures error-free GPU processing, especially in situations where the GPU may run out of memory.

These steps drastically reduce the memory requirements for fine-tuning while performing almost on par with standard fine-tuning.
Besides all optimized fine-tuning techniques, it’s important to note that the fine-tuning process focuses on teaching the model new tasks or patterns rather than new information. It means there are better solutions than fine-tuning for tasks that require storing and retrieving additional up-to-date knowledge, such as question answering (QA).
Embeddings
The problem of demand for up-to-date information, which was not presented in training data, can be solved using semantic embeddings.
Semantic embeddings are high-dimensional numerical vector representations of text that capture the semantic meaning of words or phrases. By comparing and analyzing these vectors, similarities and differences between textual elements can be discerned.
Leveraging semantic embeddings for search enables the quick and efficient retrieval of relevant information, particularly within large datasets. Semantic search boasts several advantages over fine-tuning, such as faster search speeds, reduced computational costs, and preventing confabulation or fact fabrication. Owing to these benefits, semantic search is often favored when the objective is to access specific knowledge within a model.
To enhance an LLM with embeddings, the first step involves obtaining a collection of relevant documents containing the necessary information for the task. Subsequently, these texts are divided into coherent smaller chunks, and their embeddings are computed using a specialized model. Proprietary models like OpenAI’s text-embedding-ada-002 and open-source options like instructor-xl can be employed. These embeddings are stored in dedicated vector stores, enabling efficient search and retrieval operations.
Once the necessary preparations are completed, the next stage involves inference. Let’s consider a question answering task where Wikipedia pages serve as the source of information. Initially, the question is embedded using the same model used for generating the embeddings from external knowledge sources. Subsequently, the top-K similar text chunks are retrieved using the resulting query vector and then are provided as input context along with the question to the LLM.

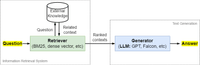
By utilizing this additional context, the enhanced LLM demonstrates its capability to answer questions based on information that may not have been present in its training data or is private. This ability to leverage external knowledge and context allows the LLM to handle a broader range of queries and address information gaps. It is a powerful tool for tasks that require accessing and generating responses based on external or private information.
Conclusion
Large Language Models have emerged as powerful tools in modern NLP, revolutionizing the way we approach and solve complex language-related problems. These models offer out-of-the-box solutions for various tasks, providing quick and accurate responses with their inherent language understanding capabilities. Furthermore, LLMs have the flexibility to tackle more sophisticated and nuanced challenges through fine-tuning and leveraging contextual embeddings. Their ability to generalize from limited examples, incorporate external knowledge, and adapt to specific domains makes them invaluable in diverse applications.







