Multiple object tracking using person re-identification

Aleksandr Dolgaryev
CTO
Today we will talk about People tracking and Re-identification. Let’s start by defining some key terms.
Multiple object tracking is the process of locating multiple objects over a sequence of frames (video). The MOT problem can be viewed as a data association problem where the goal is to associate detections across frames in a video sequence.
Multi-Target Tracking is an umbrella term for many tracking scenarios. The targets can be people, animals, cars, etc. The video can stream from one or multiple cameras. Additionally, targets could merge or split (e.g. cell tracking).
So we have N camera streams and should determine our target objects/subjects’ location at all times.
It can be very useful in retail for footfall analysis. Footfall is also known as ‘Walk-in’ and is the number of people walking into a retail store for the respective period being a day, week, month, etc. With the development of technology and IoT, it has become easier for retailers to track footfall attributes more accurately. It lets a retailer understand the success of their marketing strategy and brand power. There are huge benefits in analyzing the footfall and its attributes.
Also, people tracking is used in public security areas to recognize specific patterns for surveillance analysis and collection of information. This information ranges from age and height detection, gender identification to face recognition and person identification.
Multiple Object Tracking Framework
Detection
First of all, we decided to look at the object detection part of the Tracking Framework. Object detection is a computer technology related to computer vision and image processing that deals with detecting instances of objects of a certain class (such as humans, buildings, or cars) in digital images and videos.
For detection, we use Faster R-CNN, because this model has good accuracy with a performance for our purpose. Faster R-CNN is an end-to-end framework that consists of two stages. The first stage extracts features and proposes regions for the second stage to classify the object in the proposed region. The advantage of this framework is that parameters are shared between the two stages creating an efficient framework for detection.
-
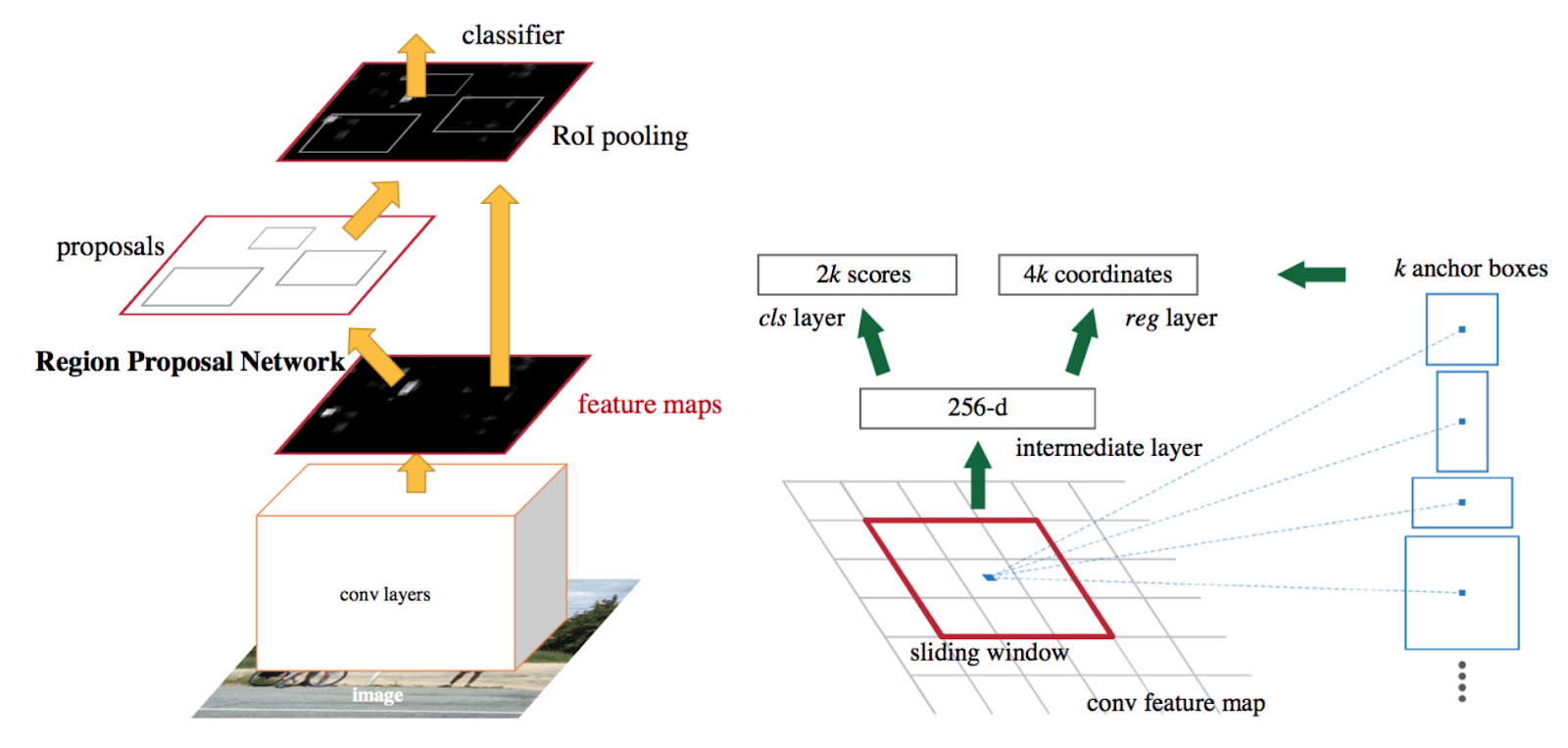
Faster R-CNN
As we said, Faster R-CNN has two networks in it: region proposal network (RPN) for generating region proposals and a network, that uses these proposals to detect objects. The main difference here with Fast R-CNN is that the later uses selective search to generate region proposals. The time cost of generating region proposals is much smaller in RPN than selective search when RPN shares the most computation with the object detection network. Briefly, RPN ranks region boxes (called anchors) and proposes the ones most likely containing objects.
Re-identification
Person re-identification (ReID) is associating images of the same person taken from different cameras or the same camera at different points in time. In other words, assigning a stable ID to a person in a multi-camera setting. Usually, re-identification is constrained to a small-time period and a small area covered by cameras.
For ReID we use Models with Triplet Loss from In Defense of the Classification Loss for Person Re-Identification, Yao Zhai, Xun Guo, Yan Lu, Houqiang Li. Usually, in supervised learning, we have a fixed number of classes and train the network using the softmax cross entropy loss. However, in some cases, we need to be able to have a variable number of classes. In people recognition, for instance, we need to be able to compare two images of unknown people and say whether they contain the same person or not.
Triplet loss, in this case, is a way to learn good embeddings for each object. In the embedding space, images from the same person should be close together and form well-separated clusters.
However, we don’t want to push the train embeddings of each label to collapse into very small clusters. The only requirement is: when given two positive examples of the same class and one negative example, the negative one should be farther away than the positive one by some margin. This is very similar to the margin used in SVMs, and here we want the clusters of each class to be separated by the margin.
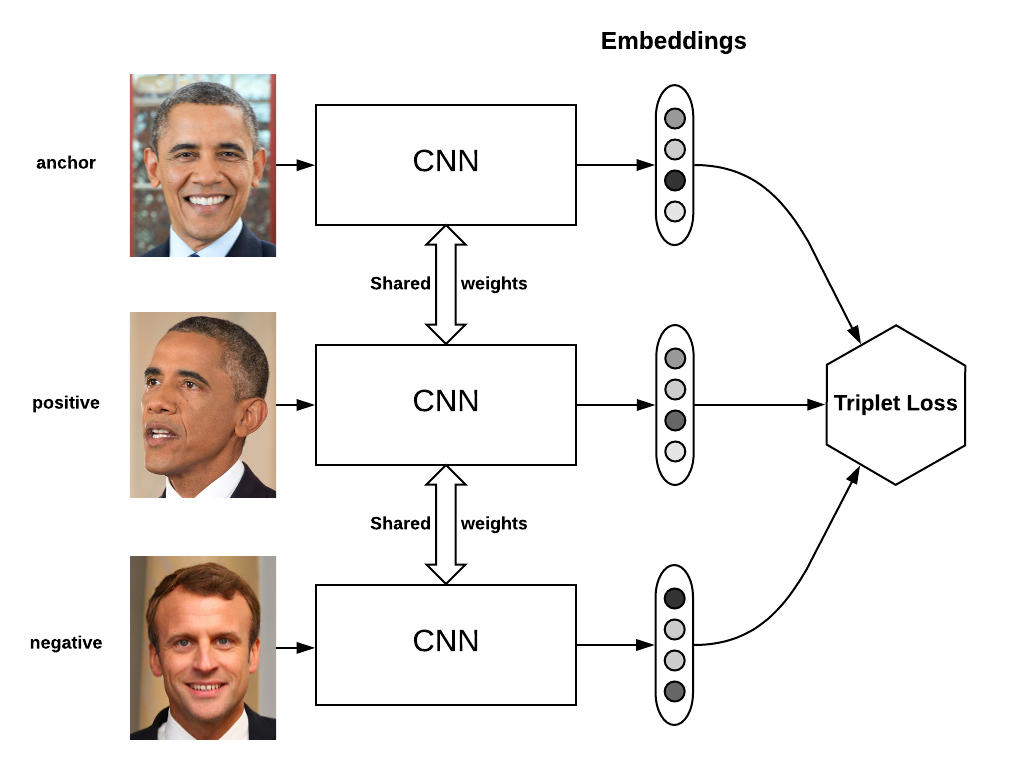
To formalize this requirement, the loss will be defined over the triplets of embeddings:
- an anchor
- a positive of the same class as the anchor
- a negative of a different class
For some distance in the embedding space dd, the loss of a triplet (a,p,n)(a,p,n) is:
L=max(d(a,p)−d(a,n)+margin,0)L=max(d(a,p)−d(a,n)+margin,0)We minimize this loss, which pushes d(a,p)d(a,p) to 0 and d(a,n)d(a,n) to be greater than d(a,p)+margins(a,p)+margin. As soon as nn becomes an “easy negative”, the loss becomes zero.
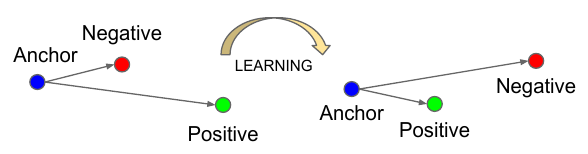
But as our experience shows the neural network needs a wide variety of images in its training data. This is because it builds embeddings based on sizes and colors, so if a person on a given image is not fully visible or frames have different brightness or contrast the model will be inaccurate.
-

Market 1501 dataset
-

Custom dataset
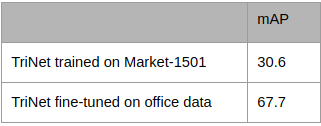
So we take Triplet-based network pretrained on Market-1501 and it has accuracy 30.6 mAP, not so good. Next, we collected additional data from our office and tagged it. A week later we had around 1000 frames with 37 people. After that, we fine-tuned the network and achieved 67.7 mAP.
Tracking
The next logical step is to use tracking. Because we are working with a sequence of frames, we can use information from previous frames to improve detection and re-identification on the current frame. We used the Deep SORT framework and add our detection and reID models to accomplish this.
Simple online and real-time tracking (SORT) is a simple framework that performs Kalman image space and frame-by-frame data association using the Hungarian method with a bounding box overlap. This simple approach achieves good performance at high frame rates. The idea is to use some off-the-shelf model for object detection and then plug the results into the SORT algorithm with DEEP ASSOCIATION METRIC that matches detected objects across frames. Additionally, two classical yet extremely efficient methods, Kalman filter, and the Hungarian method are employed to handle the motion prediction and data association components of the tracking problem respectively. This minimalistic formulation of tracking facilitates both efficiency and reliability for online tracking.
A conventional way to solve the association between predicted Kalman states and newly arrived measurements is to build an assignment problem that can be solved using the Hungarian algorithm. Into this problem’s formulation, the authors integrate motion and appearance information through a combination of two appropriate metrics: one for motion information and the other for the association problem itself. They combine both metrics using a weighted sum. Instead of solving measurement-to-track associations in a global assignment problem, the authors introduce a cascade that solves a series of subproblems.
MOT Evaluation Paradigms
As different end-users have different needs, application specific measures have been designed to serve these needs. It is in principle impossible to establish one single measure of performance that satisfies end-users in all scenarios.
Сonsider the example below where a suspect goes through an airport. Three trackers are deployed, and we are tasked with recommending one tracker to airport security.
At the entrance, the suspect is tagged as ID1 by each tracker, and each tracker at some point incorrectly assigns to the suspect the tag ID2. Depending on the frequency or length of these confusions, two evaluation paradigms stand out.
![]()
Paradigm #1
The first evaluation paradigm examines how often a target is lost or reacquired. It measures errors through identity switches, the sum of fragmentation and merge errors. This paradigm has been useful for researchers to help understand where and why trackers make mistakes. According to this paradigm, tracker a is the best choice (1 switch) and b and c are equally good (7 switches).
Paradigm #2
The second paradigm instead evaluates how often a target is correctly identified, regardless of how often it is lost or reacquired.
According to this paradigm, tracker c is the best with 83% identification recall/precision and a and b are equally good with 67% identification recall/precision. This evaluation paradigm is more useful to end-users in this case, airport security, who would prefer tracker c because it correctly infers who is where more often.
Summary
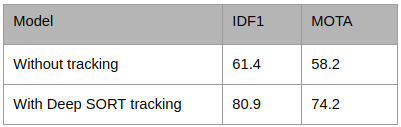
The Tracker has improved the accuracy of the whole framework. This bump in accuracy allows us to start using the system in real-world applications.
As we can see Multiple Object Tracking is not a trivial task. And we need to decompose it into parts and solve it step by step.
The video inspired to write this article.



Contact us if you have questions or ideas, and follow our blog updates.
Read more: Remote video streaming with face detection







