Livestock monitoring with ML and Computer Vision

Michael Yushchuk
Head of Data Science
The agricultural sector is one of the largest and significant branches of Europe’s economics. Agriculture is a highly developed industry. The livestock sector is an integral part of the agriculture sector and carries economic and social importance. So a big part of economics and lives depend on the agriculture and livestock sector.
There is a lot of manual routine work that can be automated. This process can increase the productivity of these sectors and decrease resource consumption such as money and people’s energy. For example, pigs need to be weighed daily to track their fitness. And this process can be automated using Machine Learning.
Pipeline

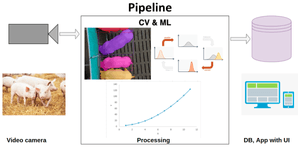
The livestock monitoring system can be implemented using a similar pipeline:
- Video cameras installation at farms and pens. This part is the hardware level. You need to take care of camera resolution, camera position and good connection with the processing server.
- Video stream processing using Machine Learning and Computer Vision techniques. This is the most interesting part. And we will describe it in the article.
- Data post-processing and visualization. Here we need to process data using statistical instruments like filters, forecasting, etc. And the main goal is to show it to the end-user simply and understandably.
ML & CV processing
In this stage, we calculate pigs’ weights using images stream from installed cameras. We are using techniques like segmentation and detection and some computer vision tricks to solve this task.
First of all, we need to determine where exactly pigs are on the image. For this, we can use computer vision techniques like object detection, instance, and semantic segmentation.
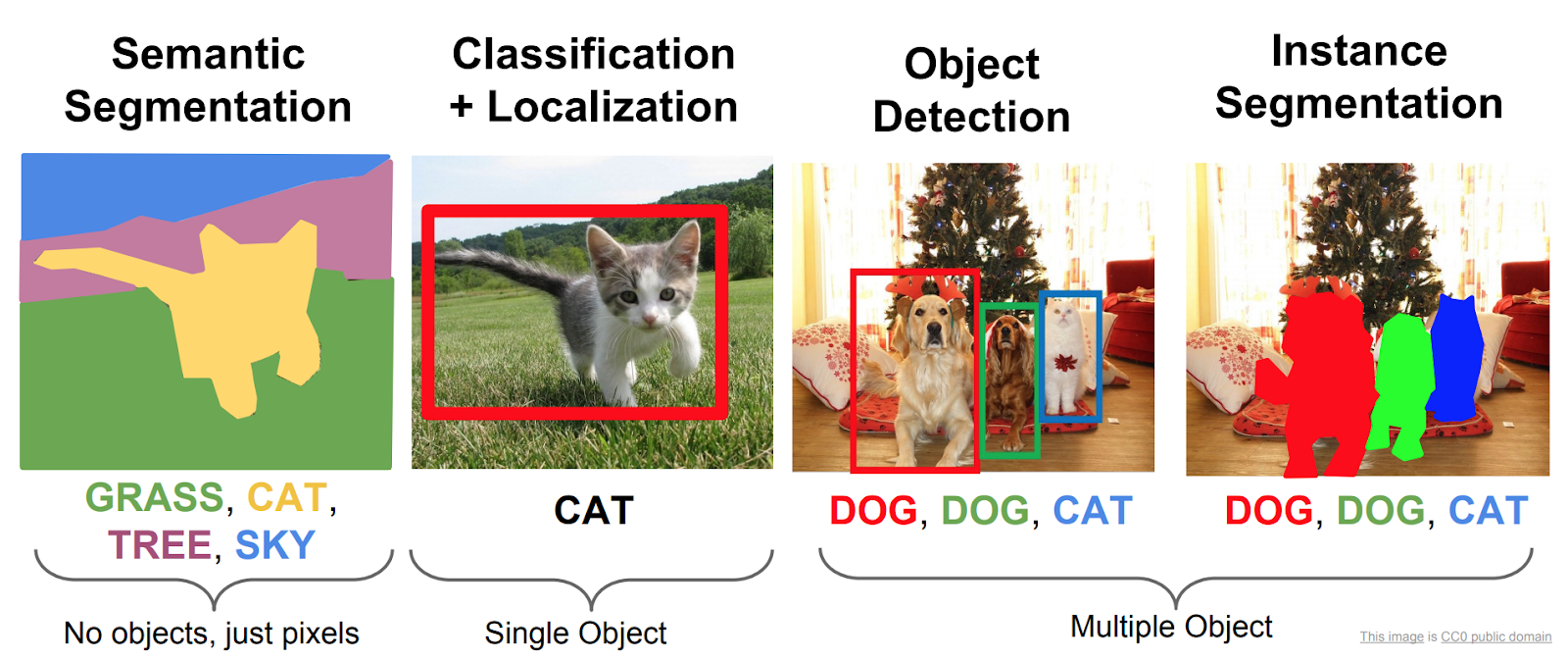
Object detection — is a technique that determines the position of an object on an image and its class (cat, dog, car…). And there can be more than one object like this per image.
Semantic segmentation — is classifying pixels on the photo to one of the predefined classes (man, cat, background…).
Instance segmentation — this technique combines two above mentioned techniques: detect objects on the image and determine which pixels belong to those objects.
All these techniques take an image as input and nowaday are implemented using neural networks.
So for accurate pigs detection better use instance segmentation. One of the best NN for this is Mask R-CNN.
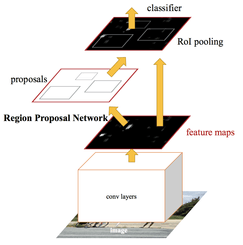
Mask R-CNN
Mask R-CNN is a kind of expansion of Faster R-CNN with its Region Proposal Network (RPN). The RPN predicts a region that contains objects with high probability. And adds one more output with a pixel map. So as the output we have the position, classes, and pixels for each object on the images.

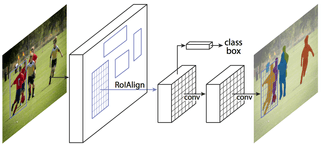
One of the most useful and simple to use implementation of Mask R-CNN is matterport implementation. They have good tutorials, documentation, and examples. Also, interesting article and implementation are The 2018 Data Science Bowl: “Spot Nuclei. Speed Cures.” Here the author describes how to improve the accuracy and speed of the network.

Now we know how much pixels belong to a pig. And we need to calculate weight using the number of pixels. It is a good task for regression. Regression is a classic ML and statistical method. Sklearn library implements a lot of supervised methods that can be used for weight prediction.


We still have one of the most difficult tasks: pig identification. In each image, we should define which pig exactly is on it. For this task, ear tags are usually used.

Usually, these tags have different colors and are visible on camera images. To detect these tags we can use multiple techniques:
Color detection using classical computer vision techniques and HSV color space
HSV (hue, saturation, value) are alternative representations of the RGB color model, designed in the 1970s by computer graphics researchers to more closely align with the way human vision perceives color-making attributes.
The HSV color space has the following three components:
- H — Hue ( Dominant Wavelength );
- S — Saturation (Purity/shades of the color );
- V — Value ( Intensity ).
The best thing is that it uses only one channel to describe color (H), making it very intuitive to specify color.

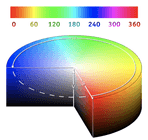
This post describes how to use OpenCV to do this.
Object detection using YOLOv3 network
You only look once (YOLO) is a state-of-the-art, real-time object detection system implemented on Darknet. Prior detection systems repurpose classifiers or localizers to perform detection. They apply the model to an image at multiple locations and scales. High-scoring regions of the image are considered detections. This model has several advantages over classifier-based systems. It looks at the whole image at test time, so its predictions are informed by a global context in the image. It also makes predictions with a single network evaluation unlike systems like R-CNN which require thousands for a single image.
To carry out the detection, the image is divided into an SxS grid (left image). Each of the cells will predict N possible “bounding boxes” and the level of certainty (or probability) of each one of them (image at the center), this means SxSxN boxes are calculated. The vast majority of these boxes will have a very low probability, that’s why the algorithm proceeds to delete the boxes that are below a certain threshold of minimum probability. The remaining boxes are passed through a “non-max suppression” that will eliminate possible duplicate detections and thus only leave the most precise of them (image on the right).\


Semantic segmentation using U-Net
U-Net is the architecture of a convolutional neural network that was developed for medical image segmentation. The architecture is pretty simple and contains two paths. The first path is the contraction path (also called the encoder) which is used to capture the context in the image. It is just a traditional stack of convolutional and max-pooling layers. And the second path is the symmetric expanding path (also called the decoder) which is used to enable precise localization using transposed convolutions. SO this network only contains Convolutional layers and does not contain any Dense layer because of which it can accept an image of any size.

But to use U-Net, we need to use multidimensional output. Because classic network works with binary data and has a 1D output mask. In our case need one mask for each color of the ear tag. For example, if there are 6 colors we need 6 output masks, and so on.
Conclusion
As we said above livestock is one of the major and important parts of the agriculture sector. And there is a lot of work that can be automated. We can use Machine learning methods and techniques in it. Also, we need to take into account that today a lot of models and technologies are in open access and can be used for this task. This allows to reduce the cost and increase the quality of agriculture.
Contact us if you have questions or ideas, and follow our blog updates.







