Intent classification and slot filling: managing web pages with natural language

Michael Yushchuk
Head of Data Science
To keep people out of tedious routines, reduce transaction costs, and increase the efficiency of our business, we are committed to automation, including the most innovative approaches, such as deep learning. One area of deep learning, natural language processing, has recently reached incredible development. We have many powerful, complex, and amazing models for Natural Language Understanding, or NLU, to extract useful information from human speech. Now we can build complex non-deterministic solutions with great generalization capabilities for such problems as determining user intents, searching for named entities, extracting answers to user questions, and even generating our own text on a human-like level.
At Quantum, we have faced the task of creating an agent for the automated manipulation with web pages. We want to automate the entire user interaction process with the website, limiting it to only inputting commands in natural language. Our task is to create a unified system – which will work without being tied to a specific website. We already have a lot of work in this area. For example, you can look at our lecture “Imitation Learning for web application testing” for the Hamburg Data Science Community. We can see many applications of this solution in web page testing, from creating stable test cases resistant to changes in the site markup to providing an inclusive QA workflow.
Core concepts of IC&SF
This time, we decided to try Intent classification and slot filling (IC&SF) models for this domain. IC&SF tasks are prevalent in creating chatbots and other cases of automated interaction with users in natural language.
Intent classification is the automated categorization of text queries based on customer goals. In essence, an intent classifier automatically analyzes texts and categorizes them into intents. It is useful to understand the intentions behind customer queries, automate processes, and gain valuable insights. We treat interactions with different UI elements in our domain as different intents. We will decide what action to perform based on the intent – clicking, typing text, etc.
The goal of slot filling is to identify slots corresponding to different parameters of the user’s query. With the help of slot-filling models, we can understand whether each word in the query has a useful semantic meaning for us. Thus, the main challenge in the slot-filling task is to extract the target entity. Slot Filling task is similar to Named Entity Recognition (NER). Both tasks use sequence tagging as an approach. While SF aims to find entities with respect to something, NER is more generic and just looks for ‘things’ that have names, like people, companies, places, etc., but doesn’t tell us what this entity refers to. We can easily redesign the model for the NER problem, but in our case, we chose SF as the one that gives more information on the output. We consider slots as UI objects that need to be interacted with, as well as various reference UI objects.
Combining all together, we can consider the problem of IC&SF in this example – “Please press this blue Login button under the password field.” For this query, the intent is “press the button,” and the slots are “Login” (button name) and “password” (textbox name anchor). So, intent classification focuses on predicting the query’s intent, while slot filling extracts semantic concepts. Using information about the user’s intent and provided slots, we can determine which action agent has to perform and which UI objects this action has to be performed.
Models
In this paper, we considered two models for the IC&SF task – JointBERT and DIET, which are state-of-the-art on open benchmarks. They solve the same problem but use opposite approaches, so comparing them to our domain is interesting. But first, we need to define the problem we are solving. Thus, intent classification is a multiclass classification task of an input sequence. In turn, slot filling is a task of multiclass token classification, i.e., class assignment of the input sequence. We will use IOB notation for sequence labeling for slot-filling tasks, where B stands for the beginning of a slot, I – inside, and O – outside. For example, in the sentence “press big Save File icon,” slot tags will be as follows – “O O B-icon-name I-icon-name O.”
JointBERT
You can find the full JointBERT description in this article. There is also a github repository for a fully implemented model with Pytorch.
The essence of JointBERT is in fine-tuning the BERT backbone with two heads, which are simple fully-connected layers – one is for intent classification, and another is for slot filling. In JointBERT, the joint objective is maximizing the conditional probability of the intent and each slot by minimizing the cross-entropy loss. You can find the JointBERT model architecture below.

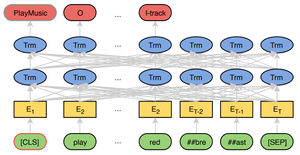
DIET
In the original article, the authors of DIET (Dual Intent and Entity Transformer) position the model as an alternative to heavy models, using complex approaches to build classification heads and transfer learning for featurization of input sequence instead of fine-tuning the backbone for specific tasks, as in JointBERT.
Authors use transfer learning with general NLU models to obtain dense features and combine them with sparse word and character-level n-gram features, then pass this sequence representation to a 2-layer transformer with relative position attention. They also create a complex training objective consisting of three parts: Named entity recognition, Intent classification, and masking.
So, unlike the JointBERT, the DIET model has a much more complex head and does not perform fine-tuning of the backbone.

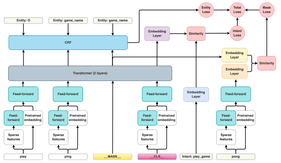
Data
Open source data
For the IC&SF task, there are two common open benchmarks – SNIPS and ATIS. The ATIS dataset contains transcripts from audio recordings of flight information requests, while the SNIPS dataset is gathered by a custom intent engine for personal voice assistants. Albeit both are widely used in NLU benchmarks, ATIS is substantially smaller – almost three times in terms of examples, and contains s times fewer words. However, it has a richer set of labels, 21 intents, and 120 slot categories, as opposed to the 7 intents and 72 slots in SNIPS.
Synthetic data for web domain
For our domain, there are no datasets for IC&SF tasks. So, we decided to create a synthetic dataset by generating sentences using different grammar schemes.
To begin with, we wrote down the intents and slots that interested us in our task. So, our intents are:
- button_press
- check_checkbox
- enter_text
- expand_dropdown
- file_upload
- icon_click
- link_click
- radiobutton_click
And the slots:
- button_name
- checkbox_name
- dropdown_name
- icon_name
- link_text
- location_anchor
- radiobutton_label
- textbox_name
- textbox_text
- upload_name
For the slots that are names of UI elements (button_name, checkbox_name, etc.), we also created additional “anchor” slots (button_name_anchor, checkbox_name_anchor, etc.). Anchor is the UI element given to specify the target more precisely. While most slots mean the names of UI elements, textbox_text means the text to insert in the specified text field, and location_anchor stands for the relative location between target and anchor UI elements (left, down, etc.). As a result, we have 8 intents and 18 slots in our dataset.
Then, for each intent, we prepared 3 grammar schemes (24 in total). Each scheme is a sentence template, and its parts – subject, predicate, and so on – are chosen randomly from a list of semantically similar words. The schemes within one intent differ in the location of the secondary members of the sentence, the word count, and the positions of the anchor inserts. You can find an example of such a scheme below:
- Detect and, Find and (slot – O)
- click, press, hit (slot – O)
- round, black, big, small (slot – O)
- Submit, Create, Load, Add, Next, New, Clear (slot – button_name)
- button_name – file, history, order, page (slot – button_name)
- button (slot – O)
- <anchor subquery>
An anchor subquery is a sentence schema generated separately and inserted into the main query. For example:
- located below, below, above, beside, next to (slot – location_anchor)
- Use, Add, Clear, Select (slot – icon_name_anchor)
- All, Task, Date, File (slot – icon_name_anchor)
Results
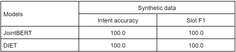
First, we can compare the quality of models on public benchmarks. The comparison table below from the DIET paper shows both models’ accuracy for intent classification and micro-average F1 score for slot filling.


As we can see, JointBERT has slightly better quality on these benchmarks. Both models perform at a level close to 100%, and these results are satisfactory.
Unstratified data
At this stage, we generated 17,000 examples from all three schemes, randomly sampling examples from all possible synonym combinations. We used 15,000 examples for training, 1000 for validation and 1000 for model testing.
We then trained JointBERT and DIET using default settings. We got excellent results – 1.0 on the test set for both intent classification accuracy and slot-filling F1 score. JointBERT trained to the top validation score much faster than DIET, and we will cover this issue in the next chapter.

During inference, we tested the models on queries formed with other synonyms. The models resist word substitutions, as one would expect from their architecture.
Experiments with stratification
In the next study stage, we decided to test the model’s robustness to queries generated from unfamiliar schemes. Our goal was to determine how well the model would cope with unusual formulations. We know that the problem of diversity of training examples is a relevant obstacle in synthesizing datasets for NLP tasks. It is described, for example, in the original SNIP paper. This problem is solved by text augmentation and also by the use of partial manual markup. But we were interested in determining the initial robustness of models to such changes in the dataset.
We again took 15,000 samples to train the models for the experiment, 1,000 for validation, and 1,000 for testing. But this time, we stratified subsamples with grammatical schemas – we generated a training sample using only 2 grammatical schemas for each intent and set aside the third scheme to generate validation and test subsamples from them.
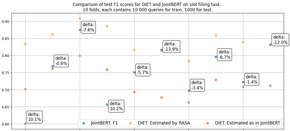
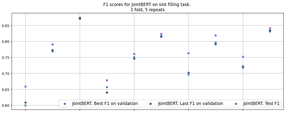
During the experiments, we found that the models behaved unstably. We ran training for both models on 10 different data generations (folds) and found that the median difference in F1 between the models is 3.5% in favor of JointBERT, as shown in figure 3. Also, STD scores for JointBERT are 8.4%, for DIET 4.2%. Please note that the DIET model is provided on the RASA framework. However, metrics calculation differs from the JointBERT implementation, so we recalculated the micro-average F1 for the DIET model and showed them both with the original RASA’s estimation in figure 3.
Moreover, JoinBERT has the same STD within one fold, as shown in figure 4. With an increase in the size of the training and validation subsets, the situation has not changed. Therefore the difference of 3.5% does not answer the question of which model is better – they both behave unstably.


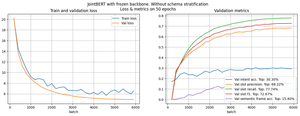
It should be noted that on the training sample, both models always have a 100% score. From this, we can conclude that the models are overfitted, and the complexities of our models cause instability. Also, since the training loss reaches the plateau much faster for JointBERT, we see that this model overtrains faster than DIET. There is an explanation for this because in JointBERT, we fine-tune all BERT layers, whereas in DIET, backbone layers are frozen.
We decided to experiment with freezing layers of JointBERT. To begin with, we trained JointBERT with a frozen backbone for unstratified data. So, the only changed weights were in the fully connected head layers. The number of epochs to convergence increased significantly, and the metrics dropped significantly, as seen in Figure 5.

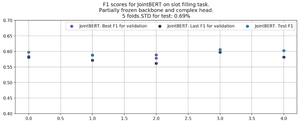
From Figure 6, in which the F1 scores on different folds are shown, we can see that freezing the JointBERT’s backbone leads to the stabilization of the network.
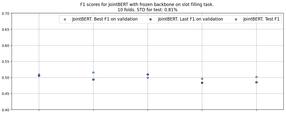
Figure 6. JointBERT performance on 5 folds with stratification. Frozen backbone.
Then we decided to unfreeze the backbone’s last layers and add new layers for Intent and Slot classification heads. After several iterations of experiments, we got the results in Figure 7. As you can see, the score has grown, especially for intent classification.

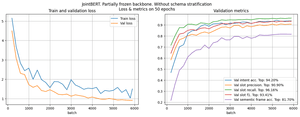
The next step was training the modified model on stratified data. The training results are shown in Figure 8. We see that intent accuracy reached 90% and slot F1 growth at 10% compared with the initial frozen model. We can understand that further experiments with modifying the last layers of JointBERT will help us achieve higher generalization and prevent overfitting.

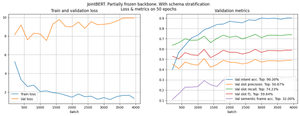
When running a partially frozen model on different folds, we will have the result in Figure 9.

Conclusions
In this study, we examined one approach to building a system of interaction between a user and the website using natural language. We tested several state-of-the-art NLP models for joint intent classification and slot-filling tasks on open benchmarks. We also generated a synthetic dataset and tested the performance of the models for our domain.
As a result, we saw that if we could build exhaustive grammatical templates for synthetic data generation, we could get excellent results for our task and embed similar systems in the pipelines of different automated systems, such as chatbots.
We have also investigated the sensitivity of the selected models to unknown grammatical constructions. We obtained results that indicate that we can partially solve the problem by modifying the network for specific datasets. In conjunction with other approaches to text data diversification, we can build a robust solution for intent classification and slot filling for different domains using the selected models.







