Comparing Object detection models’ performance on different GPUs

Ivan Lukinov
Director of Operations
In recent years Deep Learning approaches have been evolving more and more. DL has been successfully applied in a variety of different tasks ranging from recognizing a dog on a photo to parsing human speech. As time passes, models start to perform better and better, but as a side-effect, they also get bigger and more complex. Simply running most state-of-the-art deep learning models requires a pretty powerful GPU. Not to mention training those models. Not many people can afford to buy, store and maintain a rack of GPUs. This is where cloud services come into play. There you can rent different GPUs for your needs for some time while paying a small fraction of the GPU cost.
So, cloud services are useful, but what type of GPU to choose for your deep learning needs? That is what we decided to find out. We have our own GPU that we would like to compare to two different cloud GPUs that Amazon provides: Nvidia Tesla V100 and Nvidia Tesla M60. Those were chosen because they both have a Tesla architecture, but a V100 instance is more than 2.5 times more expensive compared to an M60 instance with the same amount of GPUs (p3.8xlarge and g3.16xlarge EC2 instances respectively).
As a way of comparing the GPUs performance, we chose the Object detection task. It is one of the major problems in Computer vision field, where the main objective is to find and classify different objects on an image or video. A lot of research has been conducted in this area and the best methods we have today are all based on Deep Neural Networks. We will be comparing the performance of three main modern architectures: SSD, Faster R-CNN, and YOLOv3.
A bit about the Models
Firstly, let us have a brief look at each of the models, how they differ in architecture and why they differ in speed. As we have already mentioned, 3 architectures were tested, but not 3 models. For the tests, we took two variations of SSD: SSD Mobilenet V2 and SSD Inception V2. But we will get to them a bit later, first, let’s have a look at the oldest of the architectures here — Faster R-CNN.

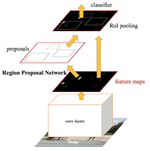
This architecture is different from any other listed here in that the detection is carried out in two steps:
- Region proposal — in this step, the neural network looks for places where it thinks the objects might be present and assigns probabilities to those regions;
- Classification — here, it looks through the proposed regions and tries to predict the class of the object and its actual presence;
SSD in general
SSD stands for Single Shot Detection, which means that this architecture unlike the one we have discussed before, does all the detection and classification in one single step. Which makes this method even faster and involves less computation overall. This is done using a different approach which is based around using “anchor boxes” and applying them at different steps of the feature extraction If you want to know more about them, take a look here. All SSD models pretty much only differ in the way they extract features.
SSD Mobilenet V2
This implementation of SSD is aimed more for the mobile market, as we can see from its name. It has some specific architectural optimizations aimed at both GPUs and CPUs of mobile phones. But generally, this network also works faster on any PC simply because of its small size. Unfortunately, it is also less accurate compared to most other models. But hey, having a small, fast and extremely accurate model is still a bit unrealistic, you have to make some tradeoffs.
If you would like to read more about Mobilenet V2, I would suggest looking at the original blog post or the ArXiv paper.
SSD Inception V2
Here feature extraction is done using the famous Google’s Inception V2 model. In that model, they have introduced convolution Factorization. In general, it has a great balance of size, speed, and accuracy. It’s one of the most commonly used models out there. Also, if you would like to read more about the Inception architecture in general and how it has improved over time and v2 in particular, go here or here accordingly.
YOLO v3


Every article mentioning the YOLO architecture must include the iconic picture of the dog, bicycle and truck. So, there you go
YOLOv3, as well as the SSD, utilizes the concept of anchors. And authors of YOLO have also decided that softmaxing detection classes are not the way to go because some of the classes might not be mutually exclusive like Person and Man. So, the classes are predicted separately using the logistic regression and then the most probable one is assigned to the detection.
And as always some further reading articles: official YOLO website, paper.
GPU specification comparison


Test runs results






Summary

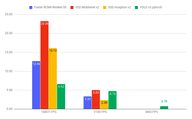
We were quite surprised by the performance of the cloud GPUs. According to the specifications, those GPUs should be at least on the same level, if not faster, than a cheaper gaming GPU. This can be explained by the fact, that the gaming GPU was built to quickly make a lot of calculations on relatively small data, while the cloud GPUs are intended for the long and heavier computations with much bigger data. So, training some huge deep neural network on gigabytes of data will be way faster on the cloud GPU like V100, but inference time on those will not be the greatest (at least from our experience). Unless you need to run inference on gigabytes of data constantly.
Contact us if you have questions or ideas, and follow our blog updates.







