A quick introduction to NLP

Michael Yushchuk
Head of Data Science
Natural Language Processing or NLP is an area of Data Science, Machine Learning and Linguistics that focuses on processing people’s language. NLP used to be one of the slowest developing areas. When Computer Vision has been using fancy neural networks since the dawn of AlexNet, NLP was lagging. In recent years the area is starting to get closer and closer to the development speed of CV.
You might have heard about the Transformer, BERT, XLnet, and Ernie. But what are those? What is NLP overall, how do machines understand our speech, and do they? Read on to know more. This article has a complementary Google collab notebook where you will be able to fiddle with some of the libraries and approaches I describe here in real-time.
Let’s begin by getting familiar with some of the NLP basics. Machines cannot understand text or speech in the way we humans do. All of the text on a PC/phone/cloud server is stored in bytes that just encode the way the letters should be displayed. A computer does not understand the meaning of what it stores. Pretty much as with images in computer vision.
But Google translate seems to know over 40 languages and can freely translate one into any other. GPT-2 network that OpenAI has recently released produces scaringly human-like texts. So, how does all of it even work? There’s a lot to learn about NLP, and it’s a good idea to start with the basics and move from the beginning of the whole process. The first step in pretty much all of Data Science is preprocessing. So, let’s get to it!
Text cleaning
Most of the data that we produce, especially in social media, is cluttered and erroneous. As you can see in the notebook example, when working with real data, you might run into some problems with random HTML tags for some reason being present in the text. Or maybe some @mentions from Twitter or #hashtags. Those can be useful if you would like to associate the data with some topic or entity like a country or a person, but for other tasks like sentiment analysis, this might result in data bias. Regular expressions are almost always a way to go in these cases.

RegEx is a very powerful tool that is pretty often feared because of its complexity. You can use it to remove redundant spaces in your text, extract phone numbers, dates, etc… Regexes can vary from relatively small and easy-to-understand ones like \d+ to match one or more numbers in a row to something like this (?P<base>[a-z\d_-]+)@(?P<domain>[a-z\d_-]+)\.[a-z]{2,4} to match an email and separate it into two parts. Not only this but it can also be used for the next step of our NLP pipeline — tokenization.
Tokenization
Tokenization is a process of splitting text into tokens. A token is the smallest building block of the text, and it varies depending on the task, language, and approach. It can be a word or a punctuation symbol, a character, or a bunch of characters. Every library for NLP has some form of a tokenizer written, and each of them has its nuances. You can play around with a few different ones in the complementary notebook I have mentioned. Here we will take a look at a few basic approaches.
Delimiters
Delimiters or special separating characters is one of the most simple approaches. You might now want to use this for text parsing because using delimiters is quite limited, pun intended. In Python, any string has a method split() that can split the string into a series of substrings using the supplied character. I.e. “This is a sentence.” can be split on whitespace into (‘This’, ‘is’, ‘a’, ‘sentence.’). The last word has a dot attached to it. This will happen to every punctuation symbol as well as an apostrophe. Also, if you have two spaces in a row for some reason, this will return an empty string in between those.
RegEx
There are two main approaches to tokenization using RegExes: finding tokens or finding delimiters. For the second task, it even has a built-in special character — \b. It matches the empty string, but only at the beginning or end of a word. And the word in RegEx is defined as a sequence of word characters — \w. Those can also be used to find words (containing A-Z, a-z, 0–9 and _). See the corresponding notebook section for more.
Rule-based
The name says it all. Every language has its own set of grammatical and morphological rules. Those can be translated into a bunch of ifs (not exactly) and used to split the text into tokens. Rule-based tokenizers also handle punctuation very intelligently. So, at the end of the sentence, a dot should be separated from the rest of the words, but the `Mr.` should be left as one token. This is the most common way of text tokenization.
Byte Pairwise encoding (BPE)
Originally this technique was used for data compression, but later it was also adapted to the field of NLP. The main principle here is to look for recurring patterns in the text and encode those into another symbol. There’s a cool example of this in Wikipedia. In NLP this is mainly used for specific languages like Chinese or Turkish. Why Turkish you might wonder? Take a look at this or this. This type of language is called agglutinative. And BPE will help you to separate such huge words into small pieces. This greatly decreases the size of the vocabulary and will also help in generalization. Because it will still understand previously unseen worlds that are constructed from these parts that it already knows.
Token preprocessing
Good. Now we have not a continuous sequence of characters but a sequence of defined tokens that can be directly translated into features. But can we do more with those? There are several ways you can preprocess words after the text has been tokenized.
Stop Words removal (+rare words)
This is a very simple approach that is based on the idea that if the word occurs in almost every text all the time, then it probably carries little information. This visualization helps get the big picture. The opposite is true for very rare words. A model that you might be training can just overfit for these very rare words (tokens). So, it will pretty much disregard all other tokens in a text. I.e. a mistyped word ‘graet’ in a good movie review might become a very strong indicator of a review being good.
The list of basic frequent words in the English language can be found in most NLP libraries, but each one contains a different list because the criteria for putting a certain word in such a “Stop words” list is not fixed.
Removing very rare words from your vocabulary and replacing them with <UNK> — unknown token, is still a very good and relevant idea, whereas removing the stop words in most current Deep Learning NLP pipelines leads to worse performance.
Stemming and Lemmatization
As can be derived from the name, the main goal of the first approach is to cut the word down to its stem or base. It is mostly a rule-based truncation. Thus it can sometimes shrink some very different words to the same stem. The examples can be found in the notebook.
In the second approach, we transform the word into its lemma. So, words like ‘am’, ‘was’, ‘were’ would get converted to just ‘be’. This approach is more sophisticated and produces far better results than just stemming. Try comparing the results of stemming with this one.
WordNet
WordNet is a very comprehensive database of the English language. There you find the lemmas, stems, synonyms, antonyms and some other interesting properties and neighbors of the word. More information and even a web-based search can be found on the official site. This tool can be used for data augmentation, which is done to create more training data with minimal costs. E.g. you can randomly change some of the words in the corpus for its synonym. It’s not the most reliable way, but might be worth a try.
POS / NE Tagging
Some words might have different meanings depending on what Part Of Speech (POS) it is or if it is a part of some company’s name — a Named Entity (NE). There are a series of different methods on how to get and use this information. Writing your own POS or NER (Named Entity Recognition) tagger might not be the easiest task. But fear not, there are already plenty of methods implemented and several different neural network architectures to train.
Using those tags can be as simple as appending the tag to the word itself. So, instead of ‘live’, you will have ‘live_VB’, where VB means a verb. If some word or a series of words is a named entity like a PERSON or COMPANY, you can concatenate them into a single vector. Because separating the parts of a named entity might bring an unexpected bias to the model’s predictions.


E.g. let’s imagine there’s a company called ‘Good Dudes’. And somebody wrote a review: ‘Good Dudes are awful’. Here the sentiment model might get confused because there are both words ‘good’ and ‘awful’ in the same sentence. Which of them is the part of the review? Right now it cannot tell. But if you apply NER tagging, you will see that the words ‘Good Dudes’ are very likely to be a named entity, like a company name. Using the name of the company as a feature in a classification task is a bad idea because if people only write bad reviews for the company, the model will just remember that the company is bad. And eventually, it might classify even legitimately good reviews for the given company as being bad. So, the best practice is to remove the name or change it for its NER tag. Now the review is ‘COMPANY are awful’, and it’s obvious what sentiment score to give it.
Constituency parsing
This processing approach can give you information about the words’ relations in the sentence. This information can be very crucial to sentiment tasks. Imagine a review ‘This movie was not very good’. If we just take a word by word approach, then this review is very likely to get classified as positive. The word ‘not’ can be used in both positive and negative reviews, but the word good is more likely to be present in a positive one.

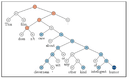
But, if we apply the constituency parsing, we will see that the phrase ‘very good’ gets modified by the word ‘not’, which inverts the meaning, thus making the review negative. All this looks easy on paper, but implementing such an approach is hard. And most state-of-the-art sentiment models do not use this information directly.
Coreference resolution
We, people, can understand that the word ‘it’ in the sentence ‘Chicken did not cross the road because it was too tired’ corresponds to the ‘Chicken’, and not the ‘road’. But for machines, this is a relatively hard task to solve on its own. Using such information can be tricky if you do this by hand, but the models based on the Transformer architecture or some other type of attention might learn to represent this information in a way that it helps. It’s not completely understood what kind of info it does capture. But still, more on that in our later publications.
Feature creation
Now we have an augmented sequence of tokens, but we need numbers or sequences of them to feed to our machine learning algorithms. Most of the approaches use a vocabulary — a simple mapping from tokens to numbers. We do not pass those directly to the algorithm but rather use them as indices. So, for example, you have the word ‘good’ in your sentence. If this word is #4 in your vocabulary, you would put a 1 for feature #4. Now, it’s time to get a more detailed look at different feature creation methods.
Bag of Words
As the name suggests, this means representing the text as just a bunch of words and treating the word presence/absence/count as a feature. So, each token in a sentence/text will just be converted into a long sparse vector of the length of the vocabulary, where it will only have numbers at the indices of the present words. Going back to our example of the word `good`, it might look like this: [0, 0, 0, 0, 1, 0, …, 0]
Ngrams
A way of converting a bunch of tokens of sequence length N that appear next to one another to a feature. There are unigrams — single token (pretty much bag of words), bigrams — a sequence of two tokens, trigrams — a sequence of three tokens and so on… In practice, it’s rarely a good idea to go further than trigrams because the feature matrix will become very big and sparse, which is not good.
TF-IDF (Term Frequency — Inverse Document Frequency)
The intuition behind this is to make the words that are not that common have a higher score in a given document. This is done by counting the number of occurrences of a token (term) in a current document and the number of documents it occurs in overall. The formulas can be found on Wikipedia or the sklearn page. The tf-idf can be used on its own or can be interpreted as weights for some other representation like embeddings.
Embeddings
Pretty much embeddings is just a mapping from token to a vector. Vectors can either be learned on the task like Language Modelling or Text Classification, with the model fitting. Or they can be separately precomputed using approaches made solely for this purpose, e.g. Word2Vec. A huge benefit of this approach compared to all previous ones is that it does not use a single number to represent a token, but a combination of them like [0.4322, -0.1123, …, 0.9542]. This allows to carry a lot more information and is said to even encode a meaning of the word. There is a lot to be said about the embeddings, they deserve their article.
Conclusion
Today we have taken a look at some of the basics as preprocessing, tokenization and some methods of feature creation. These are the foundations of NLP pipelines. Now we are ready to move to more advanced topics and take a closer look at some of the approaches we already know. The topic of our next article in the ‘Introduction to NLP’ series will be ‘Embeddings and Language Models’. Stay tuned!
Useful links
- fast.ai Code-First Intro to Natural Language Processing
- Stanford DeepLearning NLP course
- Pretty old, but gold NLTK NLP book







