Small objects detection problem

Aleksandr Dolgaryev
CTO
Machine learning is getting in more and more parts of our everyday lives. From the personally served ads and movie recommendations to self-driving cars and automated food delivery services. Almost all modern automated machinery ‘sees’ the world, but not like we do. They have to specifically detect and classify each object to see and acknowledge it as we humans do. While all modern detection models are good at detecting relatively large objects like people, cars, and trees, small objects, on the other hand, are still giving them some trouble. It is really hard for a model to see a phone on the other side of the room or see a traffic light from a 100m away. So today we are going to talk about why do most popular object detection models are not that good at detecting small objects, how we can improve their performance and what are other known approaches to the problem.
Reasons
All modern object detection algorithms are based on Convolutional Neural Networks. This is a very powerful approach because it can create some low-level abstractions of the images like lines, circles and then ‘iteratively combine’ them into some objects that we want to detect, but this is also the reason why they struggle with detecting small objects.
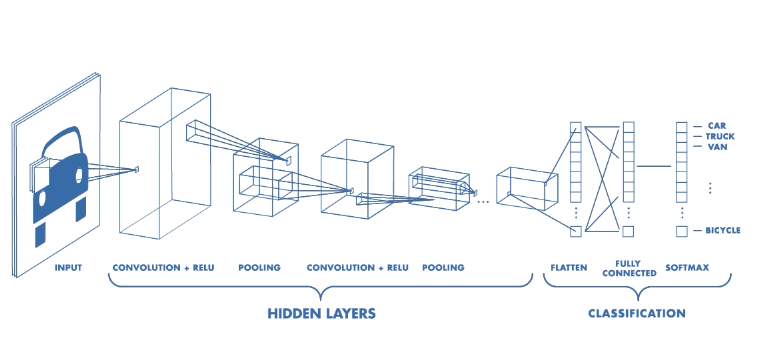
Above you can see an illustration of a generic image classification neural network. We are mostly interested in the Hidden layers part. As you can see, this network has several combinations of convolutions followed by a pooling layer. A lot of object detection networks like YOLO, SSD-Inception and Faster R-CNN use those too and quite a lot of them. Reducing the images from ~600×600 resolution down to ~30×30. Due to this fact small object features they extract on the first layers (and there are few of them to start with) just ‘disappear’ somewhere in the middle of the network and never actually get to the detection and classification steps. There are a few methods we can try to help the models see those objects better, but before improving the performance, let’s look at where it stands right now.
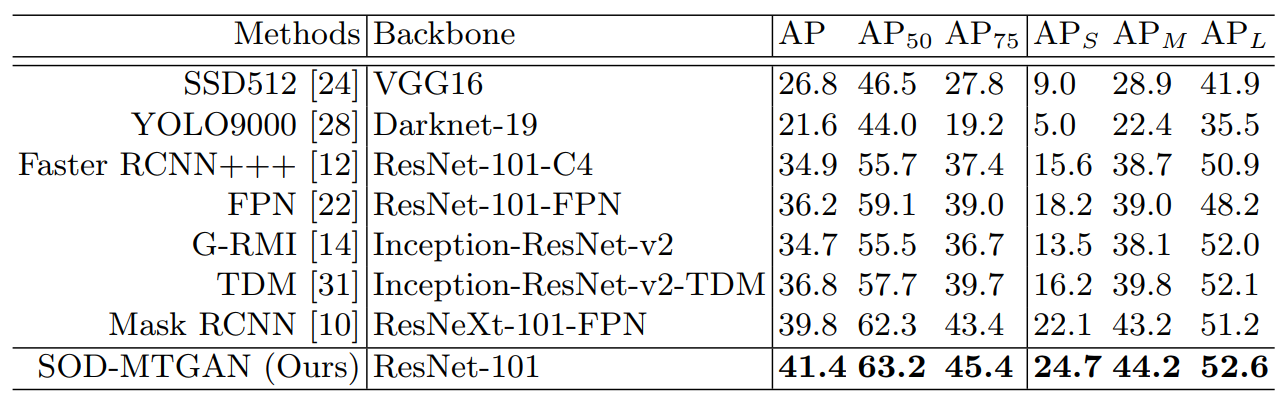
Popular models for object detection and their performance on the task
Ways to improve small object detection with minimal changes
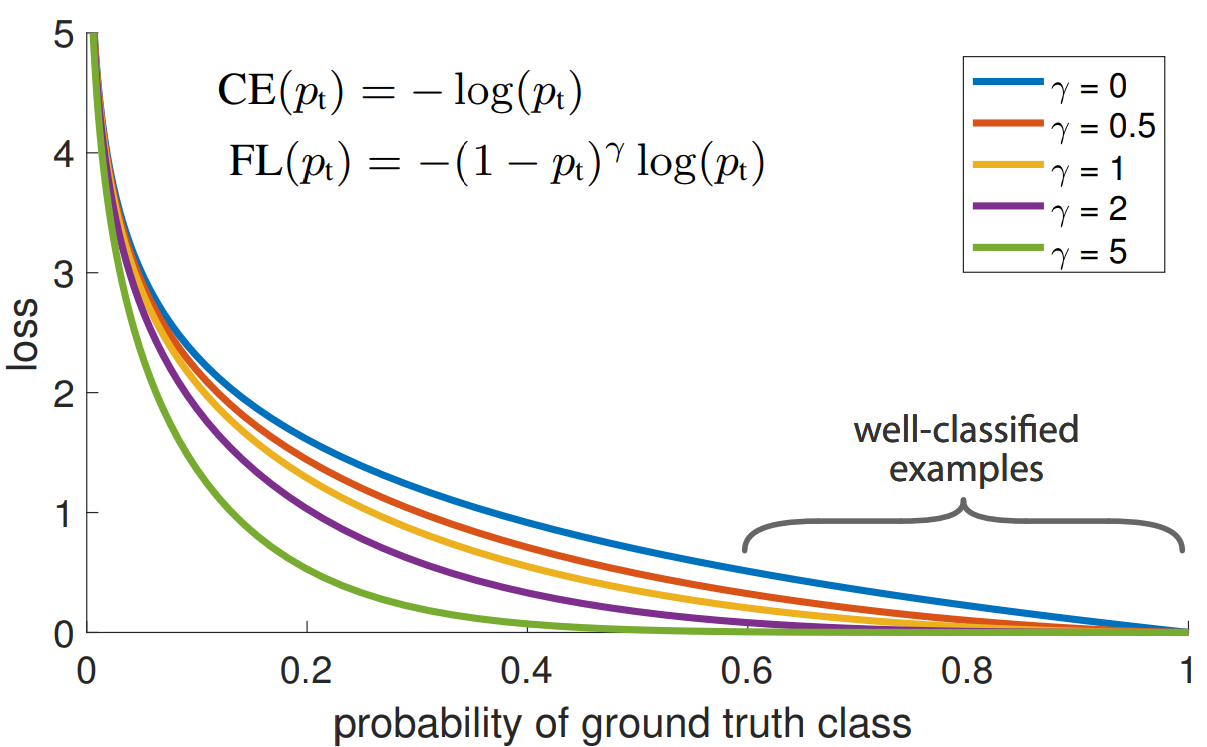
Using Focal loss
If you have a lot of classes to detect, one of the easiest ways to improve the detection of small objects and just classes that are hard to detect is using focal loss in the process of training a neural network. The main intuition here is that this loss “punishes” the network less for misclassifying classes that it can already detect pretty good and more for classes it is having problems with now. So, to further minimize the loss function, weights will start to change in such a way that will make the network pick up difficult classes better. It’s easy to see on the graph provided in the main paper itself:
Splitting image into tiles
We have personally encountered a problem with models not detecting relatively small objects. The task was to detect football players and the ball on the playing field. The game was captured in 2K resolution, so we had quite a lot of detail. But the models we were using to detect the players had way smaller input resolutions — ranging from 300×300 to 604×604. So, when we just fed the image to the network, a lot of detail got lost. It was still able to find players on the foreground, but neither the ball nor players on the other side of the field got detected. Since we had a big input image, we decided to try out the most simple solution we could think of first — split the image into tiles and run the detection algorithm on them. And it worked quite well. You can see the results of our test runs below.

While the FPS of the models dropped quite significantly, it gave the model a very good accuracy boost on the players’ detection. The ball, on the other hand, was still a problem though. We will dive deeper into how we solved it a bit later.
Using the temporal nature of images
If we have a video from a stationary camera and we need to detect the moving objects on it i.e. the football, we can utilize the temporal nature of images. For example, we can do background subtraction or just use the difference between the subsequent frames as one (or many) of the input channels. So, we might have 3 RGB channels alongside one or more additional ones. This does make us change the inputs of the network a bit, but still not that much. All we have to change is the very first input layer, and the rest of the network can stay the same and still leverage the full architecture power.
This change will be an indicator for the network to create more ‘powerful’ features for moving objects, that will not vanish in the polling and strode convolution layers.
Changing anchor sizes in the detector
Some of the current detectors use so-called “anchors” to detect objects. The main intuition here is to help the network detect objects by explicitly providing it with some information about the size of objects and also to detect several objects per predefined cell in the image.
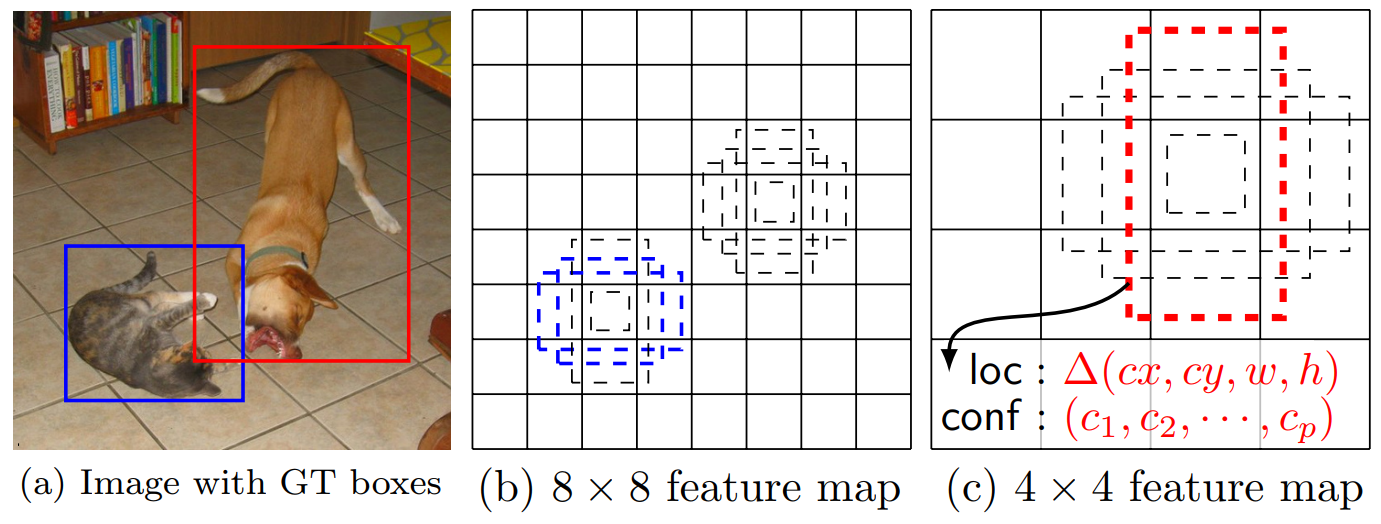
So, it’s a really good idea to change the anchors to fit your dataset. For YOLOv3 there even exists an easy way to do so. Here you will find a list of ways to improve the detection of the YOLO architectures.
Specialized models for small object detection
Approaches described above are good, but far from the best, you will most likely get better results if you use the architectures that were specifically designed to find small objects. So, let’s get to it.
Feature Pyramid Networks (FPN)
These types of networks showed to be quite effective at detecting small objects due to their interesting architecture. While networks like SSD and YOLOv3 detect objects at different scales and only use the information at those scales, a so-called Pyramidal feature hierarchy, FPNs suggests to propagate high level features down. This “enriches” abstract low-level layers with semantically stronger features the network has calculated at near its head, which in the end helps detectors pick up small objects. This simple yet effective method showed to increase the overall Average Precision on Object Detection datasets from 47.3 up to 56.9 (Table 3 in the original paper).
Finding Tiny Faces
Quite a lot of work and research has been done in this paper. I highly suggest you read it in its entirety, but we’ll sum things up here:
- Context matters, use it to better find small objects;
- Creating several networks for different scales is costly, but effective;
- Region proposal is still a good way to go if you want high accuracy;
Investigate the dataset that you network backbones were pretrained on, then try to scale your images so that sizes of objects you need to detect/classify match those of the pretraining dataset. This will reduce the training time and result in higher accuracy faster. Detecting an object of size 20×45 might not necessarily be most effective with a kernel of the same size. Just upscaling the image to twice and using the kernel 40×90 might improve the performance. The reverse is true for big objects.
F-RCNN modifications
Since on pretty much all graphs you see about the speed/accuracy comparisons among the networks, the F-RCNN is always seen at the top-right corner, people have been trying hard to improve both the speed and accuracy of this architecture. We’ll take a brief look at different ways it was modified to improve its accuracy.
Small Object Detection in Optical Remote Sensing Images via Modified Faster RCNN
In this paper, the authors have done several things. Firstly, they have been testing different pretrainined backbone networks to use in the F-RCNN for small object detection. It was found that ResNet-50 showed the best results. They have chosen the best anchor sizes that fit the dataset they have been testing the network on. Also, as well as in the previous paper about finding tiny faces, it was shown that using context around the objects significantly helps in detection. And last, but not least, they have adopted the FPN approach of combining features from high and low levels.
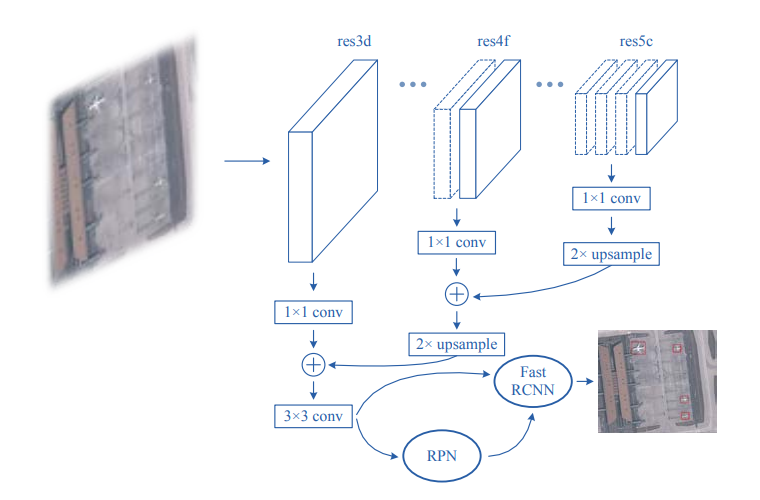
However, architecture is not the only thing they have changed and innovated upon. The training procedure was also improved and influenced the resulting performance quite a lot. The first change is a specific way of balancing the dataset for training. Instead of just leaving it as is and then tweaking the loss function for equal class learning, they balance the dataset by processing some of the images several times. This makes each epoch have a more uniform distribution of classes. The second thing they have changed is adding a random rotation. So, instead of just rotating an image by 90 or 180 degrees, they rotate them by a randomly generated angle, e.g. 13.53. This requires recalculating the bounding boxes, you can see the formulas for that in the original paper.
Small Object Detection with Multiscale Features
Authors of this paper are also using the Faster-RCNN as the main network. The modifications they have done resemble the same ideas that the FPN does — combine the features from the higher levels with the features from the lower ones. But instead of iteratively combining layers, they concatenate them and run a 1×1 convolution on the result. This is best seen in the architecture visualization provided by the authors.
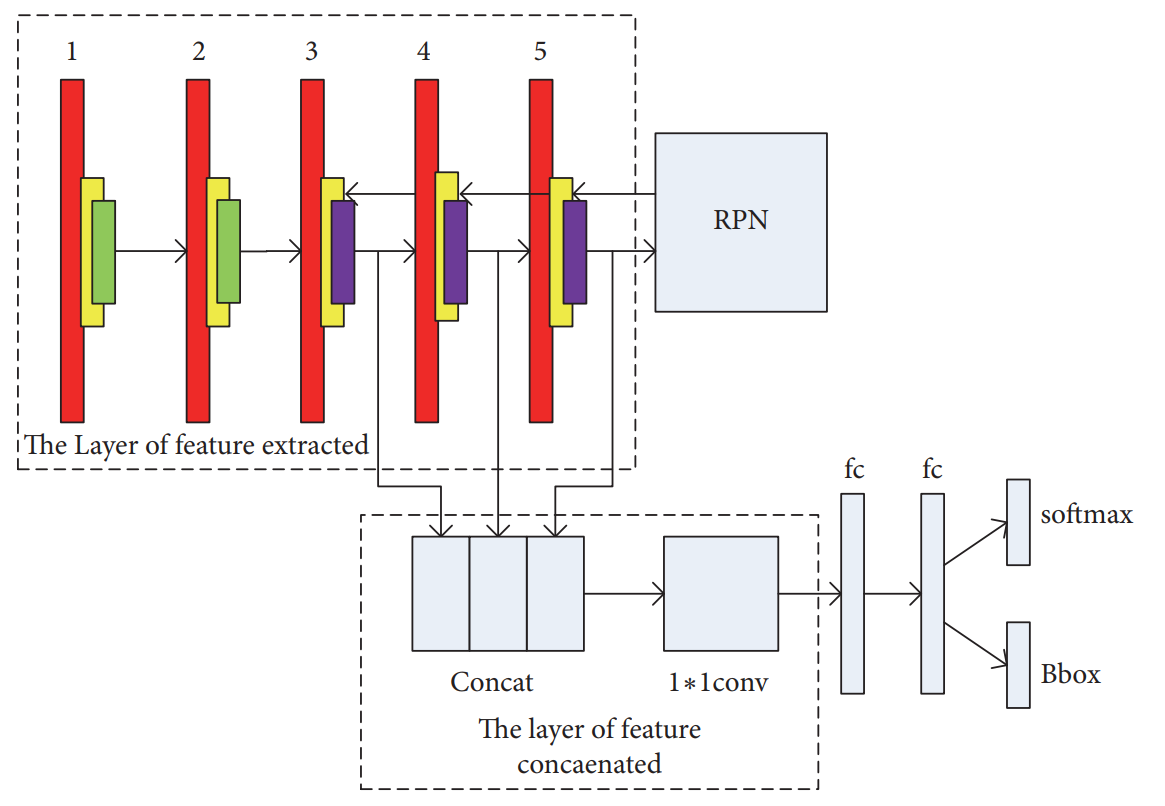
In the results table, they have shown that this approach has led to a 0.1 increase in the mAP compared to a plain Faster-RCNN.
SOD-MTGAN: Small Object Detection via Multi-Task Generative Adversarial Network
At first, after reading just the name of this approach you might be thinking: “Wait, using GANs for Object detection? What?”. But just you wait, authors of this approach have done a pretty clever thing. This might have come to your mind before: “If the objects are small, why don’t we just upscale them?”. The problem with simply making the image larger using interpolation lies in that instead of 5×5 blurry pixels we will just get 10×10 (or 20×20, or whatever the multiplication factor you set) even blurrier pixels. This might help in some cases, but generally, this gives a relatively small boost in performance at the cost of processing a larger image and longer training. But what if we had a way to actually enlarge images while preserving the level of detail? Just like they have been doing in CSI forever now. This is where the GANs come into play. As you might know, they have been shown to work pretty well for enlarging images. So-called Super-Resolution Networks (SRN) can reliably scale images up to a factor of x4, or even more if you have the time to train them and gather a dataset.
But authors are also not just simply using the SRNs to upscale the images, they train the SRN with the objective to create the images where it will be easier for the resulting detector, which is trained alongside the generator, to actually find the small objects. So, the SRN here is used not only for making a blurry image look good and sharp, but also for creating descriptive features for the small objects. As you can see in Picture 2, it worked quite good and provided a significant boost in accuracy.
While the techniques above address the challenge of object size, another common problem in computer vision is adapting models to new classes with limited data. When gathering thousands of examples isn’t feasible, a different set of strategies is needed to teach a model to generalize effectively. To explore this topic further, you can read about approaches to few-shot learning.
Summary
What we have learned today:
- The small object detection is still not a completely solved problem;
- Context matters;
- Scaling images is a good idea;
- Combine outputs of different layers;
- Investigate the dataset of the pre-trained networks to better evaluate their performance and leverage it.
Contact us if you have questions or ideas, and follow our blog updates.
Read more: Comparing Object detection models’ performance on different GPUs
AI & Machine Learning
Automate repetitive visual monitoring to boost operational efficiency, reduce costly human error, and accelerate core business workflows.
Check the service






