Getting familiar with Few-Shot Learning

Aleksandr Dolgaryev
CTO
Today we will look at several approaches that allow training such a model that can generalize to new, previously not seen classes, given only a few examples.
Motivation
Usually, when it comes to few-shot learning tasks, we hear about how complex neural networks are nowadays and how much data they need to train (i.e., thousands of examples for each new class even with a network pre-trained on a large-scale dataset with base classes). Also, we have to consider the human annotation cost as well as the scarcity of data for some classes (e.g., rare animal species or events in general). It all significantly limits the applicability of current deep learning systems to learn new concepts efficiently (as we will see further, it’s still possible to train the neural network classically while having limited labeled data).
But there are other specific tasks that classical approaches can’t handle even if there is a lot of labeled data. I’m talking about systems that demand dynamic scalability. For example, let’s consider the face verification problem. Imagine you want to build a smart pass system that will let people in (by scanning their faces) only if their photos are in the database. You don’t want to retrain the model every time the database is changed. You want to train it only once and then apply it regardless of the number of classes or faces you have. It is for such types of tasks that few-shot learning is suitable.
Approaches
In this article, we will only consider approaches based on distance metric learning. The general idea of these methods is to train a model that creates a special vector space. Once such a vector (embedding) space is created, tasks such as face recognition, verification, and clustering can be easily implemented using standard techniques with embeddings as feature vectors.
One of the ways to train such a model is to use triplet loss:

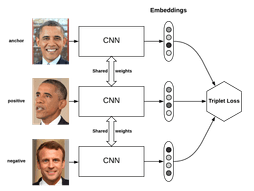
The goal of the triplet loss is to make sure that:
- Two examples with the same label have their embeddings close together in the embedding space.
- Two examples with different labels have their embeddings far away.
If you want to learn more about triplet loss, we have it covered in the Multiple Object Tracking using Person Re-identification article.
Another way is to use siamese networks:
Siamese networks (Bromley, Jane, et al. “Signature verification using a” Siamese” time-delay neural network.” Advances in neural information processing systems. 1994.) are networks that have two identical subnetworks, which share the same parameters and weights.

The goal of these networks is to predict whether two images belong to the same category or not. In general, we learn image representations via a supervised metric-based approach with Siamese neural networks and further reuse that network’s features for few-shot learning without any retraining.
Classification problem
As fascinating as this concept is, there aren’t many tasks that demand dynamic scalability. What about classical image classification tasks? What if we have a small amount of labeled data or none? These questions are answered by the authors of a closer look at the few-shot classification article.
They have compared a simple baseline model that follows the standard transfer learning procedure of network pre-training and fine-tuning with three distance metric learning-based methods (MatchingNet Vinyals et al. (2016), ProtoNet Snell et al. (2017), and RelationNet Sung et al. (2018)) and one initialization based method (MAML Finn et al. (2017)). It was shown that their baseline model achieves competitive performance with the state-of-the-art meta-learning methods on both mini-ImageNet and CUB datasets.


The most unexpected results are associated with the cross-domain scenario (using mini-ImageNet as a base class and the 50 validation and 50 novel class from CUB), which is most likely to occur in reality.

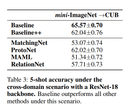
“We conduct the experiments with a ResNet-18 feature backbone. As shown in Table 3, the Baseline outperforms all meta-learning methods under this scenario. While meta-learning methods learn to learn from the support set during the meta-training stage, they are not able to adapt to novel classes that are too different since all of the base support sets are within the same dataset. In contrast, the Baseline simply replaces and trains a new classifier based on the few given novel class data, which allows it to quickly adapt to a novel”
Thus, classic simple solutions still work fine in the face of a lack of data.
Useful links
A good way to figure something out is to try applying it. The Kaggle Humpback Whale Identification Challenge has just recently ended. In this competition, you had to identify a whale by the picture of its fluke. Analyzing its public kernels is an excellent way to start with siamese networks and triplet loss.
Also, some tricky implementation details about triplet loss can be found in Triplet Loss and Online Triplet Mining in the TensorFlow blog post.
Contact us if you have questions or ideas, and follow our blog updates.
Data Science Services
Quantum applies advanced statistical analysis, predictive modeling, and ML algorithms to extract patterns, validate hypotheses, and make data-driven decisions from complex datasets.
Check the service






